- Research article
- Open access
- Published:
Systematic identifiability testing for unambiguous mechanistic modeling – application to JAK-STAT, MAP kinase, and NF-κ B signaling pathway models
BMC Systems Biology volume 3, Article number: 50 (2009)
Abstract
Background
When creating mechanistic mathematical models for biological signaling processes it is tempting to include as many known biochemical interactions into one large model as possible. For the JAK-STAT, MAP kinase, and NF-κ B pathways a lot of biological insight is available, and as a consequence, large mathematical models have emerged. For large models the question arises whether unknown model parameters can uniquely be determined by parameter estimation from measured data. Systematic approaches to answering this question are indispensable since the uniqueness of model parameter values is essential for predictive mechanistic modeling.
Results
We propose an eigenvalue based method for efficiently testing identifiability of large ordinary differential models and compare this approach to three existing ones. The methods are benchmarked by applying them to models of the signaling pathways mentioned above. In all cases the eigenvalue method proposed here and the orthogonal method find the largest set of identifiable parameters, thus clearly outperforming the other approaches. The identifiability analysis shows that the pathway models are not identifiable, even under the strong assumption that all system state variables are measurable. We demonstrate how the results of the identifiability analysis can be used for model simplification.
Conclusion
While it has undoubtedly contributed to recent advances in systems biology, mechanistic modeling by itself does not guarantee unambiguous descriptions of biological processes. We show that some recent signal transduction pathway models have reached a level of detail that is not warranted. Rigorous identifiability tests reveal that even if highly idealized experiments could be carried out to measure all state variables of these signaling pathways, some unknown parameters could still not be estimated. The identifiability tests therefore show that the level of detail of the investigated models is too high in principle, not just because too little experimental information is available. We demonstrate how the proposed method can be combined with biological insight, however, to simplify these models.
Background
Several large and detailed mathematical models for signal transduction pathways exist in the literature. Lipniacki et al. [1] model the NF-κ B pathway using 15 state variables and 29 parameters. Yamada et al. [2] introduce a system of ordinary differential equations that describe the JAK-STAT pathway with 31 state variables and 52 parameters, and Schoeberl et al. [3] describe the EGF pathway with a model that comprises 103 variables and 98 parameters. Models of this kind can provide a concise and unambiguous representation even of very complex signaling pathways. However, since usually some of their parameters are not known, these models pose demanding parameter estimation problems. Two fundamental problems must be considered in this context: 1) the larger the number of unknown parameters in a model, the larger the amount of quantitative data necessary to determine meaningful values for these parameters. 2) Even if appropriate experimental data are available, model parameters may not be uniquely identifiable [4]. Ultimately, reliable predictive mathematical models can only be created after addressing these two problems.
Parameter identifiability has been paid little attention to in the recent systems biology literature. Exceptions exist, however. Swameye et al. [5] carefully check the identifiability of their JAK-STAT model. The authors propose a small model (four state variables and six parameters) and demonstrate that the model provides quantitatively reliable predictions despite its small size. In the field of HIV/Aids modeling differential algebraic techniques have been used to prove identifiability [6–8] for models of similar size. Other examples can be found in [9, 10].
The problem of testing identifiability amounts to answering the following question: given a mathematical model of a system together with system input and output data, are the model parameters uniquely determined? The identifiability tests investigated here can be carried out before experimental data are available. To this end a model is used first to generate simulated data. Subsequently, it can be checked whether the model parameters are uniquely defined by the simulated data. Only if identifiability can be assured for the model and the simulated data it is reasonable to continue with lab experiments, identifiability tests with experimental data, and, eventually, parameter estimation. In the present paper we exclusively use simulated data.
Several notions of identifiability exist. We attempt a brief and informal summary of the essential ideas here. Stricter terminology is introduced in subsequent sections. Essentially, a model is called globally identifiable if a unique value can be found for each model parameter such that the model reproduces the measured or simulated output data. If, in contrast, a finite number of points in the model parameter space can be found, for which the model reproduces the output data the model is called locally identifiable. Finally, if an infinite number of parameter values exists that reproduce the model input-output behavior, the model is considered to be unidentifiable. Independently of these three notions we need to distinguish between at-a-point identifiability on the one hand and structural identifiability on the other hand [11, 12]. These two concepts distinguish two classes of methods for identifiability testing from one another. Methods for at-a-point identifiability testing can only be applied if candidate values for the model parameters are known a priori. This situation arises, for example, when parameter values for a model have already been published in the literature, as is the case for the signaling pathway models investigated here. In contrast, all mathematically and biologically possible parameter values must be considered as candidate values, if no information on the model parameter values is known a priori. In this case we speak of structural identifiability testing.
Several techniques exist for analyzing structural identifiability. These methods are based on power-series expansion [13], transfer function analysis [14], differential algebra [6, 12, 15], interval arithmetics [16], state isomorphisms [17–19] or semi-infinite programming [20, 21]. These methods are, however, either restricted to linear models or to models with less than 10 states and parameters in the nonlinear case [22].
For large nonlinear models only methods for testing local at-a-point identifiability are feasible. A number of methods to test local at-a-point identifiability have been proposed in the literature. Some of these aim at determining the largest subset of identifiable parameters [23, 24], other methods are tailored to finding the unidentifiable parameters [25, 26], or to finding parameters that do not affect the input-output behavior of the model [27, 28]. All these methods are based on the sensitivity matrix of the model responses (for details see section Methods for local at-a-point identifiability testing). In contrast to the approaches mentioned so far the method introduced in [29] does not depend on sensitivity information. This method repeatedly estimates parameters with randomly chosen start values and extracts dependencies between parameters with a statistical method. The data used for the parameter estimation steps is created by simulating the model at a nominal parameter point. The approach does not belong to the class of methods for at-a-point identifiability testing, since it is delocalized by using the above mentioned random multistart approach for parameter estimation. Consequently, the method is more rigorous than the discussed at-a-point identifiability tests, but not as rigorous as the structural methods.
The examples treated here turn out not to be locally at-a-point identifiable, therefore it is not reasonable to consider stricter concepts of identifiability. In the sequel the term identifiability will refer to local at-a-point identifiability if not noted otherwise.
We compare the methods for identifiability testing introduced by Yao et al. [24], Jacquez and Greif [25], and Degenring et al. [27], which for ease of reference we refer to as the orthogonal method, the correlation method, and the principle component analysis (PCA) based method, respectively. Specifically, we would like to establish which of these approaches is the method of choice for identifiability testing of large signal transduction pathway models. We omit the method published by Brun et al. [23] due to its combinatorial complexity. Similarly, the method proposed by Hengl et al. [29] is omitted, because it proved to be too computationally demanding for the examples treated here. The method was tested with default settings. When applied to the smallest of the models treated here, the wall clock computation time was about 15 hours in contrast to wall clock computation times of less than a minute for the methods compared here. When applied to the JAK-STAT model, the method proposed by Hengl et al. [29] did not finish within a week. It was therefore not included in the comparison. Finally, we note an interesting approach has only very recently been proposed by Chu and Hahn [30]. Since this approach solves a problem that is similar to, but after all different from, the identifiability tests addressed here, it is not included in the comparison. All results are compared to results found with our own method [31], which we refer to as the eigenvalue method for short. The eigenvalue method is an extension of an approach published by Vajda et al. [26]. We note the eigenvalue method has independently appeared in a recent paper by Schittkowski [32].
This paper has three contributions: 1) we reveal that three well established models of signal transduction are not identifiable, and demonstrate how results from identifiability studies can be used to simplify these models. 2) We suggest an efficient numerical method for identifiability testing of large nonlinear systems of ordinary differential equations in general, and 3) we compare our method to three previously published methods.
This paper is structured as follows. We start by reviewing the theory of identifiability and introduce the four methods for local at-a-point identifiability testing compared here. Subsequently, the three pathway models used in the case studies are introduced and each of the models is analyzed with each of the methods. Insight from this analysis is used to simplify the models.
Methods
In this section we will first introduce the mathematical system class and give a more concise definition of identifiability. We focus on local at-a-point identifiability and describe the four methods for testing local at-a-point identifiability compared here. Finally, we summarize the three signaling pathways and the corresponding models.
System Class
The concept of identifiability applies to a large system class. Here we treat models of the form

since many biological signaling pathways can be represented by systems of this form. In equation (1)  ,
,  ,
,  and
and  denote the state variables, the parameters, the inputs, and the outputs of the dynamical system, respectively. A biological parameter, for example a kinetic constant, corresponds to a component p
k
of the parameter vector. The functions f and h map from an open subset
denote the state variables, the parameters, the inputs, and the outputs of the dynamical system, respectively. A biological parameter, for example a kinetic constant, corresponds to a component p
k
of the parameter vector. The functions f and h map from an open subset  onto
onto  and
and  , respectively, and are assumed to be smooth. Note both a lab experiment and a simulation are uniquely defined by the initial conditions x(0) = x0 and the values of the inputs u(t) from t = 0 to the final time t = t
f
. Both an experiment and a simulation result in values of the outputs y(t) at successive points
, respectively, and are assumed to be smooth. Note both a lab experiment and a simulation are uniquely defined by the initial conditions x(0) = x0 and the values of the inputs u(t) from t = 0 to the final time t = t
f
. Both an experiment and a simulation result in values of the outputs y(t) at successive points  in time
in time

where n t denotes the number of measurements or stored simulation results, respectively. In the present paper, output data of the form (2) is obtained from simulations with models that have been adjusted to experimental data by other authors before [1–3].
The solution of equation (1) that results for a particular choice of initial conditions x0, parameters p, and inputs u(t) is denoted by

The solution of equation (1) and its derivatives with respect to the parameters are computed with the integrator DDASPK [33]. The output behavior of the model is given by the response function

Concept of identifiability
Here we summarize the notions of identifiability as necessary for the paper (see [4] for a review). Assuming that the inputs u(t), the initial conditions x0, and the measurement times t i are given, the different notions of identifiability can be defined as follows.
Definition 1: The parameter p
k
of the model (1) is called globally structurally identifiable if, for all admissible values  and all
and all  ,
,

implies

Definition 2: The parameter p
k
of the model (1) is called locally structurally identifiable if, for all  , there exists a neighborhood
, there exists a neighborhood  such that for all
such that for all  , equations (5) imply equation (6).
, equations (5) imply equation (6).
The parameter vector p is called globally structurally or locally structurally identifiable if all its components p k are globally structurally or locally structurally identifiable, respectively. Global and local at-a-point identifiability are defined as follows.
Definition 3: Let be a point in the parameter space of the model (1). The parameter p
k
of the model (1) is called globally at-a-point identifiable at the point p* if, for all  , equations (5) imply equation (6).
, equations (5) imply equation (6).
Definition 4: Let be a point in the parameter space of the model (1). The parameter p
k
of the model (1) is called locally at-a-point identifiable at the point p* if there exists a neighborhood such that for all , equations (5) imply equation (6).
The following subsection will introduce the four methods for at-a-point identifiability testing compared in this work.
Methods for local at-a-point identifiability testing
The compared numerical methods for local at-a-point identifiability testing are based on the sensitivity of the model outputs at discrete time points t k , k ∈ {1,..., n t }, with respect to the parameters. The sensitivity information is stored in the n y n t × n p dimensional sensitivity matrix S. S is a block matrix that consists of time dependent blocks s(t i ) of size n y × n p [34]:

The entries of s(t i ) are called sensitivity coefficients. For a nominal parameter vector p*, given x0, and fixed time t k with k ∈ {1,..., n t }, they are defined as

Essentially, the sensitivity coefficients describe how sensitive the system output is to changes in a single parameter. If the model output is highly sensitive to a perturbation in one parameter we can consider this parameter to be important for the system behavior. In contrast, a parameter that has no influence on the outputs is a candidate for an unidentifiable parameter. Linearly dependent columns of the sensitivity matrix imply that a change in the system outputs due to a change in one parameter, say p j , can be compensated by changing some or all of the dependent parameters p k , with k ≠ j. If dependencies exist, parameter estimation will fail or result in non-unique parameter values [26]. The correlation and orthogonal method are based on this idea.
For ease of presentation, we first give a detailed introduction to the eigenvalue method proposed here. The remaining methods are summarized briefly only, and the reader is referred to the appendix for more details. Since all methods analyze at-a-point identifiability, nominal values for the parameters are required. For the test cases treated here parameter values are available from the literature [1–3] and denoted by plit.
Eigenvalue method
The eigenvalue method is similar to the method published by Vajda et al. [26]. The eigenvalue method proposed here differs from the approach proposed by Vajda and coworkers in that a manual inspection of eigenvalues and eigenvectors is not necessary here. As a result, an automatic analysis of large models becomes feasible. We first describe the eigenvalue method and subsequently describe differences to the method published by Vajda et al. [26] in more detail.
We consider the least squares parameter estimation problem that amounts to minimizing cost functions of the form

with respect to p, where the y i (t j ) are the measured or simulated data introduced in equation (2). In Gaussian approximation, the Hessian matrix H of equation (9) has the entries

for k, l ∈ {1,..., n p }. As indicated in equation (10), H can be expressed in terms of the sensitivity matrix S introduced in equation (7). H is a symmetric matrix and therefore its eigenvalues are real. Furthermore, H is positive semi-definite.
In order to study the identifiability of the system in equation (1) for given x0, u(t) and for nominal parameters  we first solve equation (1) by numerical integration and subsequently calculate H as given by equation (10). We set p* to parameter values taken from the literature plit in all calculations. All identifiability tests carried out in the present paper therefore amount to asking whether the investigated signaling models are identifiable at the literature parameter values plit. As pointed out already in the Background section, identifiability tests of this type clarify whether a given model is reasonably detailed even before experiments are carried out. In this sense, the identifiability of a model at nominal or literature values for its parameters is considered to be a necessary condition for its practical identifiability with measured data.
we first solve equation (1) by numerical integration and subsequently calculate H as given by equation (10). We set p* to parameter values taken from the literature plit in all calculations. All identifiability tests carried out in the present paper therefore amount to asking whether the investigated signaling models are identifiable at the literature parameter values plit. As pointed out already in the Background section, identifiability tests of this type clarify whether a given model is reasonably detailed even before experiments are carried out. In this sense, the identifiability of a model at nominal or literature values for its parameters is considered to be a necessary condition for its practical identifiability with measured data.
Let λjand ujdenote the j th eigenvalue and the corresponding eigenvector of H, respectively. Assume the eigenvalues to be ordered such that  , assume the eigenvectors ujto be normalized such that ujTuj= 1, and assume p* to minimize equation (9). Consider the change of ϕ when moving from p* in a direction αujfor some real α. Gaussian approximation yields
, assume the eigenvectors ujto be normalized such that ujTuj= 1, and assume p* to minimize equation (9). Consider the change of ϕ when moving from p* in a direction αujfor some real α. Gaussian approximation yields

where the linear order is zero, since p* is is a minimum by assumption. Since Huj= λjujand ujTuj= 1, the last equality in equation (11) holds. Equation (11) implies that ϕ does not change when moving from p* to p* + Δp if Δp = αujfor any eigenvector ujwith λj= 0 and any real α. In words, the directions ujcorresponding to λj= 0 are those directions in the parameter space along which the least squares cost function is constant. We call these directions degenerate for short. In the particular case of

where the entry 1 is in position k, the model is not identifiable with respect to the k th component  . The approach proposed here will therefore remove this parameter from consecutive calculations by fixing to
. The approach proposed here will therefore remove this parameter from consecutive calculations by fixing to  . In general however, ujwill not be of the special form (12), but ujwill be a vector with more than one non-zero entry, therefore the choice of k is not obvious. In this case, we select a k such that
. In general however, ujwill not be of the special form (12), but ujwill be a vector with more than one non-zero entry, therefore the choice of k is not obvious. In this case, we select a k such that  , and remove the k th component of p* from the parameter estimation problem by fixing it to its literature value. In the examples treated below this choice of k turns out to be appropriate in all cases. In general, this might not be the case, however. There might be entries of
, and remove the k th component of p* from the parameter estimation problem by fixing it to its literature value. In the examples treated below this choice of k turns out to be appropriate in all cases. In general, this might not be the case, however. There might be entries of  , l ≠ k, with an absolute value
, l ≠ k, with an absolute value  close or equal to the maximal value
close or equal to the maximal value  . We call such entries and the corresponding parameters co-dominant, since together with
. We call such entries and the corresponding parameters co-dominant, since together with  they dominate the degenerate direction. A simple example for a system with co-dominant parameters is given in Appendix A. We will discuss the issue of co-dominant parameters for the examples treated here in the Results section.
they dominate the degenerate direction. A simple example for a system with co-dominant parameters is given in Appendix A. We will discuss the issue of co-dominant parameters for the examples treated here in the Results section.
In practical applications the smallest eigenvalue will typically not be zero but close to zero. In this case an eigenvalue cut-off value ϵ ≈ 0, ϵ > 0 needs to be specified. An eigenvalue λ1 <ϵ is considered to be small enough to be treated as zero. Note λj≥ 0 for all j since H is positive semi-definite.
The proposed algorithm splits the set of parameter indices {1,..., n
p
} of a given model into two disjoint subsets which we denote by I and U. Upon termination, the sets I and U = {1,..., n
p
} - I contain the indices to the identifiable and the unidentifiable parameters, respectively. We denote the current number of elements in I by n
I
and the current elements in I by  . The algorithm proceeds as follows.
. The algorithm proceeds as follows.
-
1.
Choose Δt, t f , ϵ. Set p* = p lit. Set I = {1,..., n p }, n I = n p , and U = ∅.
-
2.
If I is empty, stop. The model is not identifiable with respect to any parameter in this case.
-
3.
Fix the parameters p k , k ∈ U to their literature values and consider only the p k , k ∈ I to be variable. Formally, this corresponds to setting p to
 and treating all remaining parameters p
k
, k ∈ U as fixed numbers.
and treating all remaining parameters p
k
, k ∈ U as fixed numbers. -
4.
Calculate ϕ(p*) according to equation (9). Calculate the Hessian matrix of ϕ with respect to the parameters p k with k ∈ I and evaluate it at p = p*. Calculate the eigenvalues λ jand corresponding eigenvectors u jof the Hessian matrix. Assume the eigenvalues to be ordered such that
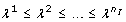 . Assume the eigenvectors to be normalized.
. Assume the eigenvectors to be normalized. -
5.
If λ 1 ≥ ϵ ,stop. The model is identifiable with respect to the parameters p k for all k ∈ I.
-
6.
If λ 1 < ϵ ,select k such that
 . Remove k from the set I, add k to the set U, set n
I
to the current number of elements in I, and return to step 2.
. Remove k from the set I, add k to the set U, set n
I
to the current number of elements in I, and return to step 2.
 and treating all remaining parameters p
k
, k
and treating all remaining parameters p
k
, k 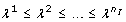 . Assume the eigenvectors to be normalized.
. Assume the eigenvectors to be normalized. . Remove k from the set I, add k to the set U, set n
I
to the current number of elements in I, and return to step 2.
. Remove k from the set I, add k to the set U, set n
I
to the current number of elements in I, and return to step 2.The order in which parameters are removed from I determines the ranking of parameters from least identifiable to most identifiable.
The method is similar to the approach introduced by Vajda et al. [26]. These authors also analyze the eigenvectors that correspond to small eigenvalues of the Hessian matrix, but they focus on the dependencies between eigenvectors that arise due to special parameter combinations of the form p1/p2 or p1·p2 in the model. In a two step procedure Vajda et al. first decide which parameters to lump together (for example, p new = p1·p2) and subsequently recalculate the eigenvalues and eigenvectors for the system with the new lumped parameters. These two steps are repeated until the smallest eigenvalue is sufficiently large. The lumping step requires manual inspection of the eigenvalues and eigenvectors of the Hessian matrix. While the approach proposed by Vajda et al. worked very well for their example with 5 parameters, it becomes infeasible for models with considerably more parameters. The examples treated in the next section demonstrate that our approach, in contrast, can be applied to models with up to at least a hundred parameters. Moreover, our approach can be carried out automatically, while the approach suggested by Vajda et al. was never intended for this purpose.
Correlation method
The correlation method was first introduced by Jacquez and Greif [25] who compared identifiability results achieved with the correlation method to analytical results obtained with a transfer function method (see [14] for a review). Jacquez and Greif [25] consider only small linear compartmental models with up to 3 states and 5 parameters. In most of the examples the correlation and the transfer function method were in agreement.
In the systems biology literature the correlation method was applied by Zak et al. [9] to investigate identifiability of a large genetic regulatory network (nonlinear, 44 states and 97 parameters). More recently, Rodriguez-Fernandez et al. [10] embedded the correlation method into their framework for robust parameter estimation in order to exclude unidentifiable parameters from parameter estimation.
The central idea of the correlation method is to find unidentifiable parameters by investigating the linear dependence of the columns of S (for details see Appendix B). The correlation method approximates linear dependence by calculating the sample correlation [35] of two columns  of S. The sample correlation is given by
of S. The sample correlation is given by

where



In equations (13)–(16) corr(S.
i
, S.
j
), cov(S.
i
, S.
j
), σ (S.
i
), and  denote the sample correlation between S.
i
and S.
j
, the sample covariance between S.
i
and S.
j
, the sample standard deviation of S.
i
, and the mean of the entries of S.
i
, respectively.
denote the sample correlation between S.
i
and S.
j
, the sample covariance between S.
i
and S.
j
, the sample standard deviation of S.
i
, and the mean of the entries of S.
i
, respectively.
Two linearly dependent columns S. i and S. j of the sensitivity matrix give rise to an absolute value of the correlation corr(S. i , S.j) = 1. In the examples treated here, none of the parameters exhibit a correlation of exactly ± 1, however. In the numerical implementation of the method, two columns of S are considered correlated if the absolute value of their correlation is equal to or larger than 1 – ϵ c , where ϵ c ∈ [0, 1] is a parameter of the algorithm. We stress that while ϵ c is a tuning parameter, the comparison of the identifiability methods is not affected by the choice of ϵ c . As explained below, we systematically vary ϵ c over its entire range 0 ≤ ϵ c ≥ 1 in the comparison.
When applying the correlation method to the pathway model examples, two problems arise regularly that have not been discussed by Jacquez and Greif [25]. For one, the method detects pairs of correlated parameters, but there is no criterion which one of the parameters from a pair to consider unidentifiable. Moreover, if more than one pair of correlated parameters is detected, there is no criterion to choose among the pairs.
In order to mitigate these ambiguities we introduce the total correlation

where

and L denotes the set of indices of those parameters that have not been found to be unidentifiable in any previous iteration. We select the parameter with the highest total correlation for removal. Some cases remain, however, in which two parameters have the same total correlation. In these cases we pick one parameter at random.
In order to be able to compare results to those of the other methods, we use the correlation method to rank model parameters from least identifiable to most identifiable. More precisely, we initially set ϵ c = 0 and L = {1... n p } and calculate the total correlations (17) for all parameters in L. If parameters with nonzero total correlations exist we select the parameter with highest total correlation to be unidentifiable and remove its index from L. If no such parameter exists we increase ϵ c until nonzero total correlations occur. The order in which parameters are removed from L creates a ranking of parameters from least to most identifiable. The algorithm is described in detail in Appendix B. Based on the ranking of parameters the method is compared to the other three approaches. The comparison is explained in detail in the subsection entitled Method comparison.
Principal component analysis (PCA) based method
Degenring et al. [27] introduce three criteria based on PCA that rank the influence of parameters on model output. Parameters that do not affect the model outputs are unidentifiable by definition and can be removed from the model equations. Degenring et al. successfully use their approach to simplify a complex metabolism model of Escherichia coli K12. A complete description how to get a full ranking using the three criteria can be found in [28]. A pseudo code description of the method can be found in Appendix C.
The PCA based method differs from the other methods described here in that it does not use the sensitivity matrix S as defined in equation (7) but a truncated matrix which we refer to by  . This matrix is defined as
. This matrix is defined as

where i ∈ {1,..., n
y
}. While the sensitivity matrix S as defined in equation (7) describes all responses in one matrix, is created for each response r
i
separately.
Three PCA based criteria are applied to each of the n
y
matrices 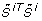 . As a result 3n
y
parameter rankings are created, which we represent by 3n
y
lists
. As a result 3n
y
parameter rankings are created, which we represent by 3n
y
lists

of integers  , where j ∈ {1, 2, 3} and i ∈ {1,..., n
y
}. The first ranking position
, where j ∈ {1, 2, 3} and i ∈ {1,..., n
y
}. The first ranking position  and the last ranking position
and the last ranking position  contain the index of the parameter with the lowest and the highest influence on the model output r
i
, respectively. The lower index j ∈ {1, 2, 3} denotes the criterion by which the ranking is calculated. We will explain one of the criteria in more detail in order to give the reader an idea of the method. The remaining two criteria are summarized in Appendix C. All 3n
y
rankings are integrated into one ranking by applying a strategy described in [28], which we briefly summarize below.
contain the index of the parameter with the lowest and the highest influence on the model output r
i
, respectively. The lower index j ∈ {1, 2, 3} denotes the criterion by which the ranking is calculated. We will explain one of the criteria in more detail in order to give the reader an idea of the method. The remaining two criteria are summarized in Appendix C. All 3n
y
rankings are integrated into one ranking by applying a strategy described in [28], which we briefly summarize below.
Let, 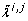 and
and 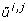 denote the j th eigenvalue and corresponding eigenvector of , respectively, and assume the eigenvalues to be ordered such that
denote the j th eigenvalue and corresponding eigenvector of , respectively, and assume the eigenvalues to be ordered such that  . For each i ∈ {1,..., n
p
} evaluate the first criterion as follows.
. For each i ∈ {1,..., n
p
} evaluate the first criterion as follows.
-
1.
Set L 1 = {1,..., n y }.
-
2.
For q from 1 to n p
-
Find r l such that
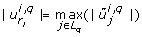 .
. -
Set
 = r
l
.
= r
l
. -
Set Lq+1= L q - {r l }.
do:
-
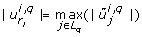 .
. = r
l
.
= r
l
.The first criterion loops over the eigenvectors starting with the eigenvector that belongs to the smallest eigenvalue. It identifies the largest absolute entry of each eigenvector and selects the corresponding parameter for removal, if this parameter has not been selected yet. The index of the k th parameter selected for removal is ranked at position k, where k ∈ {1,..., n p }.
The remaining two criteria of the PCA based method are similar but differ with respect to the process for chosing r l . For brevity we omit details and refer the reader to Appendix C. A final ranking J that incorporates all 3n y previously calculated rankings is obtained as follows. Set N q = ∅, for all q = 1,..., n p . Set J to an empty list.
For q from 1 to n p do:
-
For all j ∈ {1, 2, 3} and all i ∈ {1,..., n y } set
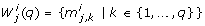 .
. -
Set
 .
. -
Only if N q ≠ ∅ append the N q to the list J.
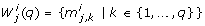 .
. .
.First note that an iteration q might exist, in which no N q is appended to J. Therefore the final number n J of elements in J is not necessarily equal to but might be smaller than n p . Further note that entries of J do not necessarily correspond to indices of single parameters but to sets of parameter indices. Therefore, a ranking position J i might contain several parameter indices an internal ranking of which cannot be obtained. This ambiguity hampers not only the interpretation of the ranking result but also the comparison with the rankings produced by the other methods. We describe a strategy to deal with the latter problem in section entitled Method comparison.
Orthogonal method
The orthogonal method was developed by Yao et al. [24] to analyze parameter identifiability of an Ethylene/Butene copolymerization model with 50 parameters. In the field of systems biology the method has been applied in a framework for model identification [36] and in the identifiability analysis of a NF-κ B model [37].
We summarize the concept of the method and refer the reader to Appendix D for details. The method iterates over the columns S.
k
of the sensitivity matrix S, with k ∈ {1,..., n
p
}. Those columns of S that correspond to identifiable parameters are collected in a matrix Xqwhere q is the iteration counter. The algorithm starts by selecting the column of S with highest sum of squares in the first iteration. In iteration q + 1, q columns of S have been selected. In the order of their selection these columns form the matrix Xq. The next step essentially amounts to selecting the column S.
k
that exhibits the highest independence to the vector space V spanned by the columns of Xq. More precisely, an orthogonal projection  of S.
k
onto V is calculated and
of S.
k
onto V is calculated and  is interpreted as the shortest connection from V to S.
k
. The squared length of
is interpreted as the shortest connection from V to S.
k
. The squared length of 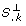 is used as measure of independence. If the length of is near zero, S.
k
is nearly linearly dependent to the columns of Xq. Conversely, a large value of
is used as measure of independence. If the length of is near zero, S.
k
is nearly linearly dependent to the columns of Xq. Conversely, a large value of  indicates that parameter p
k
is linearly independent to the columns of Xq. In the orthogonal method the parameter p
l
where
indicates that parameter p
k
is linearly independent to the columns of Xq. In the orthogonal method the parameter p
l
where  is selected as the next identifiable parameter.
is selected as the next identifiable parameter.
Essentially, the orthogonal method finds those columns of S that are as independent as possible. The quantity can be interpreted as a measure of independence that has been freed from dependencies on previously selected parameters. Therefore not only the influence of a parameter on the outputs, but also the dependencies between the parameters are accounted for by using as a measure. A visualization of the orthogonal method can be found in Appendix D.
Yao et al. [24] stop the selection process once the length of the maximal drops below a cut-off value ϵ
o
≈ 0, the choice of which is rather arbitrary. In the present paper we do not apply this cut-off criterion but merely rank all parameters from most to least identifiable where the terms most identifiable and least identifiable are used in the same sense as in the correlation method. A comparison to the results of the other methods is therefore not affected by the choice of ϵ
o
. Our approach to comparing the methods is explained in the section entitled Method comparison.
Method comparison
The central idea behind our comparison of the methods is the equivalence between the local identifiability of a model and the local positive definiteness of the Hessian matrix (10) at a minimum of the least squares parameter cost function (9) for this model. Due to this theoretical result, which has been established by Grewal and Glover [38], we can test local identifiability at a point in the model parameter space by testing the Hessian matrix (10) for positive definiteness at this point. Since the Hessian matrix is positive definite if and only if all its eigenvalues are strictly positive, we consider a model to be identifiable if the eigenvalues are bounded below by a small strictly positive number ϵ. Note the eigenvalue method proposed here is based on the same idea in that it selects those parameters to be unidentifiable that cause eigenvalues smaller than ϵ.
By virtue of the relation between local at-a-point identifiability and the eigenvalues of the Hessian matrix we can compare all four identifiability testing methods to one another with the same criterion and an unique parameter value ϵ. For a given model we first create a ranking of the parameters from least to most identifiable with each method as described in the previous four sections. For each parameter ranking we then fix the parameter considered to be the least identifiable to its literature value, calculate the Hessian matrix (10) with respect to the remaining parameters, and determine the smallest eigenvalue. In all following steps we additionally fix the next least identifiable parameter and recalculate the Hessian and smallest eigenvalue. This process is carried out until the smallest eigenvalue exceeds ϵ. The parameters that need to be fixed in order for the smallest eigenvalue to exceed ϵ are considered to be the unidentifiable parameters. Clearly, the smaller the set of unidentifiable parameters, the larger the set of identifiable parameters or, equivalently, the larger the number of parameters for which the least squares parameter estimation problem can be solved. In this sense we consider the method to be the best one that results in the smallest number of unidentifiable parameters in our comparison.
Note in contrast to the other methods, the ranking created with the PCA based method does in general not contain one but several parameters. In such a case we fix all parameters ranked at the same position at once and reevaluate the smallest eigenvalue of the Hessian matrix. The last ranking position  created by the PCA based method contains the indices of all parameters that have not been ranked previously. Fixing of parameters p
k
, with k ∈ , would therefore not leave any parameter unfixed. For this reason we consider the PCA method to have failed, if fixing of all parameters with indices in
created by the PCA based method contains the indices of all parameters that have not been ranked previously. Fixing of parameters p
k
, with k ∈ , would therefore not leave any parameter unfixed. For this reason we consider the PCA method to have failed, if fixing of all parameters with indices in  does not lead to a value of the smallest eigenvalue larger than or equal to ϵ.
does not lead to a value of the smallest eigenvalue larger than or equal to ϵ.
Pathway model description
Having introduced the methods to be compared, we briefly summarize the three pathways and the corresponding models used for the identifiability studies.
JAK-STAT pathway
The Janus Kinase (JAK) – signal transducer and activator of transcription (STAT) pathway is triggered by cytokines and growth factors. The pathway has an impact on the expression of genes that regulate diverse cellular processes, such as cellular proliferation, differentiation, and apoptosis. A detailed model of the Interferon-induced JAK-STAT pathway is given by Yamada et al. [2]. This model describes the following signal transducing steps. Upon ligand binding the receptor dimerizes thus triggering the activation of receptor-associated JAK. Activated JAK immediately phosphorylates the receptor complex, enabling the binding and subsequent phosphorylation of cytoplasmic STAT. Phosphorylated STAT can dimerize, and finally, dimerized STAT is imported into the nucleus. Here it activates target genes, one of which is the suppressor of cytokine signaling 1 (SOCS1), an important mediator of negative feedback.
EGF induced MAP kinase pathway
Mitogen-activated protein (MAP) kinases are involved in mitosis and the regulation of cellular proliferation. The Epidermal Growth Factor (EGF)-induced MAP kinase pathway is centered on a three kinase cascade that terminates with the dual phosphorylation of the third, so-called MAP kinase. EGF stimulation leads to dimerization of the EGF receptor. The dimerized EGF receptor triggers the phosphorylation of Raf, the first kinase of the cascade. Raf, in turn, phosphorylates the mitogen extracellular kinase, MEK, the second kinase in the cascade, which finally phosphorylates the MAP kinase (extracellular signal-related kinase, ERK). Phosphorylated ERK regulates several proteins and nuclear transcription factors and controls the expression of target genes. The model published by Schoeberl et al. [3] additionally includes the internalization of EGF receptor and two further modules: an SH2-domain containing protein (SHC) dependent module and an SHC independent one.
NF-κ B pathway
Nuclear Factor-κ B (NF-κ B) is a transcription factor, which regulates genes involved in inflammation, immune response, cell proliferation, and apoptosis. In the unstimulated cell NF-κ B is captured in the cytoplasm by the protein inhibitor of NF-κ B (Iκ Bα). Upon stimulation by pathway activating signals such as the Tumor Necrosis Factor (TNF), the Iκ B kinase (IKK) is activated. Activated IKK phosphorylates Iκ Bα thus inducing its degradation. As a consequence NF-κ B is released, translocates into the nucleus and regulates effector genes. NF-κ B induces its own downregulation by inducing the production of two proteins: 1) Iκ Bα that inhibits NF-κ B by relocating it to the cytoplasm and 2) the zink-finger protein A20 that represses IKK and consequently indirectly inhibits NF-κ B.
Results
In this section the results of the identifiability analysis are reported. All simulations are carried out with literature values plit for the model parameters, which are taken from the original publications of the models [1–3]. We assume that all state variables are available as outputs, i.e. y(t) = x(t) and n y = n x . Clearly, it is far from realistic to assume all state variables could be measured in an actual experiment for any of the signaling pathways. Since even under this strong assumption the models turn out not to be identifiable, however, it is not reasonable to investigate the identifiability with fewer outputs. In fact our identifiability results show that the models are overparameterized even under the very strong assumption of all state variables being measurable. The algorithmic parameter ϵ is set to ϵ = 10-4. While this value is motivated by our experience with numerical parameter estimation problems, we admit that it is somewhat arbitrary. Note, however, the comparison of the identifiability testing methods is consistent in that the same value ϵ = 10-4 is used throughout. Output values y(t) are recorded from the simulations at equidistant points in time. The JAK-STAT model is simulated for 28800 seconds (8 hours) and the response function is recorded with a time step of Δt = 360 s. The corresponding values for the MAP kinase and NF-κ B models are 3600 s (1 hour), Δt = 120 s, and 21600 s (6 hours), Δt = 360 s, respectively. These values are not critical. Similar results are obtained with other values of t f and Δt (data not shown).
JAK-STAT pathway analysis
Figure 1 summarizes the results of the analysis of the JAK-STAT model. The figure shows the value of the smallest eigenvalue as a function of the number of fixed parameters. Before discussing the parameters that are considered to be unidentifiable by the various methods in detail, some results can already be inferred from Figure 1. In iteration i = 0, i.e. before any parameter is fixed in the model, the smallest eigenvalue λ1 equals 1.3·10-5. This implies the model is not identifiable even if all state variables x(t) are assumed to be available. The smallest eigenvalue exceeds ϵ = 10-4 after the first three parameters regarded as unidentifiable by the eigenvalue and the orthogonal method are fixed (specifically, kb7, kb30, and kb5). In contrast, the first 13 parameters ranked by the correlation method need to be fixed to obtain a smallest eigenvalue larger than the threshold ϵ = 10-4. Since the eigenvalue and orthogonal method find an identifiable model by fixing a much smaller subset of the parameters, we conclude these methods outperform the correlation method in this particular case. The PCA based method fails for this example.

Results of the methods applied to the JAK-STAT model. The graph illustrates how the value of the smallest eigenvalue changes, when one parameter is fixed in each iteration. The y-axis shows the value of the smallest eigenvalue of the Hessian matrix H. Parameters are fixed until the value of the smallest eigenvalue is larger than ϵ = 10-4.
Some of the results generated by the four methods are worth inspecting more closely. In the first and second iteration of the eigenvalue method there exists more than one dominant contribution to the degenerate direction, cf. Table 1. In the first iteration there are two co-dominant entries (last column in Table 1). The corresponding parameters are kb5 and kb30. In the second iteration there exists one co-dominant entry, which corresponds to the parameter kb5. In the last iteration no co-dominant entries exist and the parameter kb5 is solely responsible for the degenerate direction. It turns out that selecting the parameter corresponding to the maximum entry of |u1| as done here is sufficient to find a minimal set of identifiable parameters. Interestingly, we can see in this example that after three iterations our method finds the parameters corresponding to the co-dominant entry of all previous iterations.
The correlation method indicates that 13 parameters need to be fixed in order for the model to be locally identifiable (Figure 1). The sets of parameters removed by the eigenvalue and orthogonal method have only kb7 in common with the parameters selected by the correlation method. In the correlation method, the removal of parameter kb7 occurs in the last iteration and results in a clear increase of the smallest eigenvalue by a factor of about 100 (from 3.3·10-5 to 2.2·10-3, see Figure 1). Surprisingly, previous iterations of the correlation method hardly have an effect on the minimum eigenvalue.
Table 2 shows ranking J as produced by the PCA based method for the JAK-STAT model. Each ranking position J
i
corresponds to a set of parameter indices, the size of which is shown in the table. The major problem of the PCA based method becomes apparent here. Ranking J has 5 positions. Fixing the 15 parameters of the first four positions of J is not sufficient to get an identifiable model. Fixing the set of 36 parameters at the last ranking position would not leave any parameter unfixed. Therefore the method has failed in finding a set of identifiable parameters. The ambiguity of the method is apparent from positions four and five of the ranking. The sets J4 and J5 contain 8 and 36 parameters, respectively, which cannot be ranked internally by the PCA based method. It is interesting to note that the first ranking position of J is not filled until iteration 45 (data not shown), six iterations before the last iteration. No nonempty intersection of the first 44 positions of all rankings 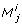 with j ∈ {1, 2, 3} and i ∈ {1,..., n
y
} exists. This indicates that large parts of the three different rankings , j = 1, 2, 3 do not agree with respect to the order of parameters.
with j ∈ {1, 2, 3} and i ∈ {1,..., n
y
} exists. This indicates that large parts of the three different rankings , j = 1, 2, 3 do not agree with respect to the order of parameters.
The parameters removed by the eigenvalue and orthogonal methods point the way to possible simplifications of the pathway models. The parameter kb7 describes the dissociation of phosphorylated STAT from the activated receptor complex. This reaction, however, is not the dissociation that immediately follows the phosphorylation of STAT by the activated receptor (Figure 2, kf6). Apart from the association of unphosphorylated STAT to the receptor (Figure 2, kf5), the phosphorylation of STAT by the activated receptor and the subsequent dissociation of phosphorylated STAT from the activated receptor (Figure 2, kf6), the model also permits the reassociation of already phosphorylated STAT from the cytoplasm to the activated receptor (Figure 2, kf7). The dissociation described by parameter kb7 is the reverse reaction to the reassociation described by kf7. We claim these steps are less important, since the key event is the phosphorylation of cytoplasmic STAT by the activated receptor. Removing kb7 alone creates a sink for phosphorylated STAT and activated receptor, since the dissociation of both species does not exist anymore. Therefore the model can only be simplified by removing both the reaction kb7 is involved in and the reaction kf7 is involved in. The main effects of these reactions are 1) to reduce the amount of free phosphorylated STAT and 2) to reduce the amount of free activated receptor. After removing both reactions, effect 1) can be imitated by appropriately decreasing those rate constants involved in reactions with free phosphorylated STAT. Effect 2) can be compensated by appropriately decreasing those rate constants that are involved in reactions with free activated receptor.

Part of the JAK-STAT model to be simplified. The activated receptor is denoted by actR. The encircled P indicates that STAT is phosphorylated.
The second fixed parameter, kb30, corresponds to the rate of dissociation of STAT from the complex formed by SOCS1 and the activated receptor complex. In order to get a simplified model that is identifiable, we may remove this step. This is justified, because the key function of SOCS1 is not its binding to STAT, but its inhibition of the activated receptor complex [39]. The latter is still ensured in the simplified model.
The third fixed parameter, kb5, describes the dissociation of receptor-bound unphosphorylated STAT. Assuming that STAT binds irreversibly to the activated receptor, the model can be simplified. In this scenario, STAT dissociates from the receptor only after STAT phosphorylation has occurred. Due to the presence of PPX, which can dephosphorylate cytoplasmic STAT, this change to the model need not result in an increase of the concentration of phosphorylated STAT.
We stress that the fact that kb7, kb30, and kb5 render the model unidentifiable does not imply the corresponding reactions do not exist. Our results imply, in contrast, that the model is too complex in the sense that these parameters cannot be determined by model based parameter estimation. Note that this result holds true even if we assume data for all the state variables to be available.
Map Kinase pathway analysis
Before any parameter of the MAP kinase model is fixed, the smallest eigenvalue of the Hessian matrix (10) equals 3.3·10-13. This implies the model is not identifiable. The eigenvalue and the orthogonal method again outperform the correlation method in that they find a significantly smaller set of parameters to be responsible for the unidentifiability of the model. The PCA based method does not lead to an identifiable method.
In the eigenvalue method the maximal components of the respective eigenvectors are near 1 (data not shown) in both iterations. As a result, two parameters, k15 and k1, can unambiguously be fixed in the first and second iteration, respectively.
The correlation method needs to fix 36 parameters to arrive at an identifiable model. Fixing the first 35 parameters does not significantly increase the smallest eigenvalue (Figure 3). Only when the last parameter is fixed a dramatic increase of the smallest eigenvalue from about 4.0·10-13 to 4.3·102 results. The parameter k15 is also removed by the eigenvalue and the orthogonal method, which indicates the importance of k15 for identifiability. The other parameter removed by the eigenvalue method, k1, is selected in the 2nd iteration of the correlation method. Therefore, the set of 36 parameters found by the correlation method is a superset of the 2 parameters selected by the eigenvalue and the orthogonal method. Closer inspection of the first iteration in the correlation method reveals a high maximal total correlation,  , of 7.98. This high value is caused by couplings of the selected parameter with eight other parameters. Despite this high total correlation value of 7.98, the removal of the corresponding parameter does not cause a significant increase of the smallest eigenvalue. Just as in the previous example, removing parameters with high correlations does not necessarily improve identifiability.
, of 7.98. This high value is caused by couplings of the selected parameter with eight other parameters. Despite this high total correlation value of 7.98, the removal of the corresponding parameter does not cause a significant increase of the smallest eigenvalue. Just as in the previous example, removing parameters with high correlations does not necessarily improve identifiability.

Results of the methods applied to the MAP kinase model. Until iteration number 17 the green curve lies below the red curve.
The ranking found by the PCA based method has five positions (Table 3). When the 17 parameters that correspond to J1, J2, J3, and J4 are fixed, the model remains unidentifiable. Fixing the parameters that correspond to J5 is not reasonable, since doing so would not leave any parameters unfixed. Due to this result, we consider the PCA based method to have failed.
In summary, the eigenvalue method and the orthogonal method identify the smallest set of parameters that needs to be fixed in order to create an identifiable model. The first parameter, k15, is involved in internalization processes represented by more than twenty reactions [3]. Comprehensive changes to this part of the model that are necessary to ensure identifiability cannot be addressed here. The second parameter, k1, describes the binding of EGF to its receptor. This essential step cannot be simplified. However, experimental data on this reaction exists in the literature [40, 41]. Our analysis suggests using this kind of independent information to fix the value of k1 before attempting to determine the remaining parameters by parameter estimation.
NF-κ B pathway analysis
For the NF-κ B pathway model, the smallest eigenvalue λ1 = 1.9·10-5 results if no parameters are fixed (Figure 4). This indicates that the model is not identifiable for the published parameter values [1]. The eigenvalue and the orthogonal method again find the same 3 unidentifiable parameters, c4a, c4, and t1. The correlation method selects a considerably larger set of 21 parameters. The PCA based method fails.

Results of the methods applied to the NF- κ B model.
In the first three iterations of the eigenvalue method, the largest components of u1 have absolute values close to one (data not shown). The method therefore selects these parameters unambiguously.
The correlation method needs to fix 21 parameters until the smallest eigenvalue is greater than ϵ. The last parameter, the fixing of which leads to an identifiable model (Table 4), has been selected with a value of ϵ c = 0.55. This is not reasonable anymore, since two columns of S with a correlation of 1 - ϵ c = 0.45 can hardly be considered correlated. Therefore we conclude that the correlation method fails for this example.
The PCA based method creates a ranking J with six positions (Table 5). Fixing the parameters that correspond to J1 to J5 does not result in an identifiable model. Fixing the parameters corresponding to J6 will not leave any parameters unfixed. Therefore the method has failed in producing an identifiable model. After fixing all parameters from J1 to J5 the resulting smallest eigenvalue λ1 = 9.5·10-5 is close to ϵ. Having a look at the parameters in the ranking J we can see that J1 contains parameter t1, and J5 contains parameter c4. Both parameters are also found by the eigenvalue and the orthogonal method.
The three parameters selected for removal by the eigenvalue and the orthogonal method indicate how to simplify the model. The first two parameters, c4a and c4, describe the only two translation steps in the model: the translation of Iκ Bα mRNA and A20 mRNA, respectively. By lumping together transcription and translation into one protein synthesis step the two unidentifiable parameters c4a and c4 can be removed from the model. The third parameter selected by the eigenvalue and orthogonal method, t1, describes the dissociation of activated IKK from Iκ α. Since this reaction is a key step of the model the only option for simplifying this part of the model is to remove IKK entirely. As a consequence A20 becomes obsolete, since the only function of A20 is the regulation of IKK. If we also remove A20, the resulting simplified model closely resembles the minimal model proposed by Krishna et al. [42].
Discussion
The eigenvalue, orthogonal, and correlation methods find the desired subset of identifiable parameters and the desired subset of unidentifiable parameters in all cases. The eigenvalue and orthogonal methods give the same results for each of the models. The subsets of unidentifiable parameters that result from the correlation method are larger than those that result from the eigenvalue or orthogonal method in all cases. The PCA based method fails for all three examples.
The four identifiability testing methods use different approaches to finding unidentifiable parameters. In order to carry out a meaningful comparison of the methods, we need a single identifiability criterion that can be applied to all methods. The positive definiteness of the Hessian matrix (10) of the least squares parameter estimation problem (9) is an appropriate and concise criterion for this purpose. Ultimately, the use of this criterion is justified by the equivalence between local at-a-point identifiability and the positive definiteness of the Hessian matrix (10). This equivalence was established by Grewal and Glower [38].
Since the Hessian matrix is positive definite if and only if all its eigenvalues are strictly positive, we consider a model to be identifiable if the eigenvalues of the Hessian matrix (10) are bounded below by a small strictly positive number ϵ. Based on experience with parameter estimation problems we set ϵ = 10-4. While this choice is arguably arbitrary, the comparisons of the methods are meaningful since the same value of ϵ is applied in all comparisons.
The numbers of unidentifiable parameters are summarized in Figure 5 for the four methods and the three models. More precisely, the Figure shows how many parameters are selected by each method to be fixed in order to obtain a Hessian matrix with all eigenvalues larger than ϵ = 10-4. From Figure 5 it is apparent that fewer parameters need to be fixed than those selected by the correlation method to obtain a positive definite Hessian matrix or, equivalently, an identifiable model in all examples. In this sense we conclude that the eigenvalue and orthogonal method outperform the correlation method. Since the PCA based method fails in all three examples, we consider it to be inferior to the other methods.

Summary of the method comparison. Since the PCA based method fails in all three cases, it is not included here.
In the remainder of the section we discuss the differences between the methods.
Eigenvalue method vs. orthogonal method
The eigenvalue method can be motivated in two different ways. For one, it can be interpreted as a convexity analysis of the minimization of the least squares cost function ϕ (9) at a nominal point p*, in parameter space. If ϕ is too flat at p*, the method identifies the parameters that cause this flatness. Secondly, the method can be looked upon as an approach to identifying linearly dependent columns of S. If STS has zero eigenvalues it is not invertible, which implies that S has linearly dependent columns. By fixing those parameters that cause STS to be not invertible, the linear independence of columns of S can be ensured. The orthogonal method selects those columns of S that have the largest possible orthogonal distance to previously selected columns. This way linearly independent columns are found. Essentially, the eigenvalue and orthogonal method use the same criterion, but the eigenvalue methods discards those parameters that render a model unidentifiable while the orthogonal method selects the identifiable parameters. Both methods give the same results for the examples treated here.
A formal analysis of the two methods reveals the computational complexity to depend on the magnitudes of n
y
n
t
and n
p
(see Appendix E). If  , as is the case in the JAK-STAT and the NF-κ B example, the eigenvalue method is an order of magnitude in the number of parameters faster than the orthogonal method. If we assume
, as is the case in the JAK-STAT and the NF-κ B example, the eigenvalue method is an order of magnitude in the number of parameters faster than the orthogonal method. If we assume  , as is the case for the MAP kinase example, the eigenvalue method is slightly faster than the orthogonal method. If n
y
n
t
≈ n
p
, both methods have the same computational complexity. We stress the complexity analysis is carried out under assumptions that are unfavorable for the eigenvalue method in that the eigenvalue method is assumed to require a full ranking to separate the identifiable from the unidentifiable parameters. In the three examples treated here this is clearly not the case, however. In fact the eigenvalue method stops after three, two, and three iterations in the JAK-STAT, the MAP kinase, and the NF-κ B case, respectively, and therefore turns out to be far less computationally expensive than under the worst case assumption used in Appendix E.
, as is the case for the MAP kinase example, the eigenvalue method is slightly faster than the orthogonal method. If n
y
n
t
≈ n
p
, both methods have the same computational complexity. We stress the complexity analysis is carried out under assumptions that are unfavorable for the eigenvalue method in that the eigenvalue method is assumed to require a full ranking to separate the identifiable from the unidentifiable parameters. In the three examples treated here this is clearly not the case, however. In fact the eigenvalue method stops after three, two, and three iterations in the JAK-STAT, the MAP kinase, and the NF-κ B case, respectively, and therefore turns out to be far less computationally expensive than under the worst case assumption used in Appendix E.
Technical drawbacks of the correlation method
From a technical point of view, the correlation method suffers from two drawbacks. These drawbacks cause the differences between the number of unidentifiable parameters found by the correlation method as compared to the orthogonal and eigenvalue method. First, the correlation corr(S. i , S. j ) is only an approximation of the linear dependency of columns of S. While two columns that are linearly dependent result in a correlation of ± 1, columns that have a correlation of ± 1 need not necessarily be linearly dependent (see Appendix F for an example). Therefore, the correlation method may find false positive unidentifiable parameters. Secondly, the correlation corr(S. i , S. j ) is only a pair wise measure for any two columns S. i and S. j of S. Linear dependence of a set of more than two columns, which does not contain a linearly dependent pair, is not detected.
Technical drawbacks of the PCA based method
The PCA based method differs from the three other methods in several aspects. The PCA based method does not use the sensitivity matrix S, but a sensitivity matrix is calculated for each component r i of the response function separately. In contrast to the other methods, couplings between the components r i are therefore not considered. A second important difference is that the PCA based method does not use a single criterion, but a combination of criteria which all must hold for a parameter to be considered unidentifiable. Due to this combination of criteria, the method does not select a single parameter in each iteration but a set of parameters. Finally, some parameters that cause S not to have full rank are not found by the PCA based method in all three examples. For this reason, we consider the PCA based method to be inappropriate for the identifiability testing of the three treated pathways.
Conclusion
We proposed a new approach to finding identifiable and unidentifiable parameters of large mechanistic models. The method, which we refer to as the eigenvalue method, was applied to existing models of the JAK-STAT, the MAP kinase, and the NF-κ B pathways. All three pathway models turned out not to be identifiable. In fact our results show that the models would not be identifiable even if all state variables could be measured precisely at a high frequency. The models must therefore be considered to be severely overparameterized. Note state identifiability investigated here is a necessary condition for output identifiability. Since the models turn out not even to be state identifiable, we refrained from further investigations of output identifiability.
The identifiability analysis reveals how to simplify the models in order to arrive at identifiable systems. For the JAK-STAT pathway an identifiable model can be obtained by simplifying only three reactions. For the NF-κ B pathway model the results lead to a simplified model that closely resembles the minimal model published by Krishna et al. [42].
We presented a detailed comparison of the proposed eigenvalue approach to three established methods for identifiability testing, namely, the correlation method [25], the PCA based method [27], and the orthogonal method [24]. These three methods and the new approach suggested are of general interest, because they can be applied to a broad class of nonlinear systems of ordinary differential and algebraic equations. Essentially, the methods were compared with respect to their ability to find an identifiable subset of model parameters for each of the three pathway models. Despite algorithmically different, the eigenvalue and the orthogonal method result in the same subsets of identifiable parameters for each of the examples. Moreover, these two methods outperform the other methods in that they find the largest subsets of identifiable parameters.
Appendix
A: Example with co-dominant parameters
We present an illustrative example to motivate the notion of co-dominant parameters. Consider the trivial system  = (p1 + p2)·x1 with y1 = x1. Using the notation introduced below equation (10), the eigenvalue λ1 equals 0 (independent of the choice of p1, p2, sampling times, and initial condition) with |u1| = (0.707, 0.707)T. From the simple model equation it is apparent that p1 and p2 are not identifiable separately, but only their sum p1 + p2 can be estimated from data. As a result, p1 and p2 are co-dominant as indicated by the result
= (p1 + p2)·x1 with y1 = x1. Using the notation introduced below equation (10), the eigenvalue λ1 equals 0 (independent of the choice of p1, p2, sampling times, and initial condition) with |u1| = (0.707, 0.707)T. From the simple model equation it is apparent that p1 and p2 are not identifiable separately, but only their sum p1 + p2 can be estimated from data. As a result, p1 and p2 are co-dominant as indicated by the result  . Fixing either one of the parameters renders the other one identifiable.
. Fixing either one of the parameters renders the other one identifiable.
B: Correlation method
We first summarize theoretical aspects of the correlation method and subsequently give a detailed description of the algorithm.
Theory
Let Δp = p - p* describe the deviation of a parameter vector p from the true parameter vector p*. For sufficiently small ||Δp||2 the response function (4) can be approximated by its linearization at p*:

for all i ∈ {1,..., n y } and j ∈ {1,..., n t }. The sum of squared errors of the linearized response functions and the measured outputs y i (t j ) reads

The last equality holds, because the y i (t j ) are assumed to be noise free measurements and p* are the true parameter values by assumption. Therefore r i (t j , p*, x0) - yi(tj) = 0 for all i ∈ {1,..., n y } and j ∈ {1,..., n t }.
Let  denote the least squares estimates of Δp, i.e. the particular values of Δp that minimize equation (20). The necessary condition for optimality
denote the least squares estimates of Δp, i.e. the particular values of Δp that minimize equation (20). The necessary condition for optimality  is equivalent to the so called normal equation STS Δp = 0. Solving the normal equation for Δp therefore results in the least squares estimate
is equivalent to the so called normal equation STS Δp = 0. Solving the normal equation for Δp therefore results in the least squares estimate  .
.
If STS has full rank, the normal equation only admits the solution Δp = 0. This implies Δp = 0, or equivalently  = p*, is the unique minimizer of the least squares function R(Δp). Consequently, the model parameters p are locally identifiable by definition. Note only local identifiability can be inferred, since an approximation by linearization was introduced. If, on the other hand, STS does not have full rank, there exists a non-trivial solution ≠ 0 of the normal equation. As a consequence, a parameter vector ≠ p* exists that results in the same model response as p*. Therefore the model parameters p are not identifiable by definition.
= p*, is the unique minimizer of the least squares function R(Δp). Consequently, the model parameters p are locally identifiable by definition. Note only local identifiability can be inferred, since an approximation by linearization was introduced. If, on the other hand, STS does not have full rank, there exists a non-trivial solution ≠ 0 of the normal equation. As a consequence, a parameter vector ≠ p* exists that results in the same model response as p*. Therefore the model parameters p are not identifiable by definition.
The matrix STS has full rank if and only if the columns of S are linearly dependent [43]. The central idea of the correlation method is to detect linear dependence of two columns of S by calculating the correlation of these columns. Parameters corresponding to columns of S with a correlation of ± 1 are considered unidentifiable.
Algorithm for the correlation method
Let C denote the matrix that contains those absolute correlation values between columns of S that exceed the threshold 1 - ϵ c . C is given by:

where S. j denotes the j th column of S and corr* (S. i , S. j ) is defined in equation (18). The algorithm proceeds in the following way:
-
1.
Choose Δt and an initial guess p*. Set ϵ c = 0, I = {1,..., n t }, and initialize U to an empty list. Calculate the sensitivity matrix S.
-
2.
Calculate the matrix C.
-
3.
For all i ∈ I calculate
 (I) as defined in equation (17).
(I) as defined in equation (17). -
4.
If I is empty, stop. The list U contains the parameter indices in the order of the least to most identifiable parameter.
-
5.
Find r q such that
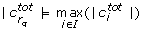 .
. -
6.
If
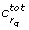 = 0, increase ϵ
c
by 0.01 and return to step 2. Otherwise, remove r
q
from I, append r
q
to the list U, and return to step 3.
= 0, increase ϵ
c
by 0.01 and return to step 2. Otherwise, remove r
q
from I, append r
q
to the list U, and return to step 3.
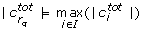 .
.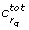 = 0, increase ϵ
c
by 0.01 and return to step 2. Otherwise, remove r
q
from I, append r
q
to the list U, and return to step 3.
= 0, increase ϵ
c
by 0.01 and return to step 2. Otherwise, remove r
q
from I, append r
q
to the list U, and return to step 3.The list U contains the desired result as explained in step 4. Note ϵ c is incremented in steps of Δϵ c = 0.01. The choice of this increment is not critical as long as it is small enough. If Δϵ c is chosen smaller than necessary the same ranking of parameters will be obtained but the algorithm may require more computation time.
C: PCA based method
We explain the second and third PCA based criterion and present the algorithm for the PCA based method. The first criterion is explained in the section entitled Methods.
Description of the second and third criterion of the PCA based method
Let and denote the j th eigenvalue and corresponding eigenvector of , respectively, and assume the eigenvalues to be ordered such that . For each i ∈ {1,..., n
p
} evaluate the second and third criterion as follows.
-
Second criterion:
Set L1 = {1,..., n y }.
For q from 1 to n p do:
-
Find r l such that
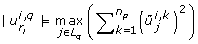 .
. -
Set
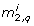 = r
l
.
= r
l
. -
Set L q+1= L q - {r l }.
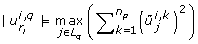 .
.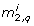 = r
l
.
= r
l
.The second criterion is based on the sum of squared eigenvector entries

Note in this sum, i and j are fixed, therefore the sum is not carried out over components of a particular eigenvector, but the l th entries of all eigenvectors are summed. The parameter with the largest value of (21) is selected.
-
Third criterion:
Set L1 = {1,..., n y }.
For q from 1 to n p do:
-
Find r l such that
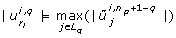 .
. -
Set
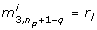 .
. -
Set L q+1= L q - {r l }.
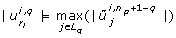 .
.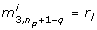 .
.The third criterion loops over the eigenvectors but, in contrast to the first and second criterion, starts with the eigenvector that belongs to the largest eigenvalue. As in the first criterion, parameters are selected based on the absolute value of the eigenvector component. The index of the parameter selected first will be placed last in ranking  , the index of the parameter selected second will be placed at position n
p
- 1, and so on.
, the index of the parameter selected second will be placed at position n
p
- 1, and so on.
Algorithm for the PCA based method
-
1.
Choose Δt and an initial guess p*. For all i ∈ {1,..., n y } let
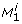 ,
, 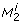 , and
, and  be empty lists. For all q ∈ {1,..., n
p
} set N
q
= ∅. Set J to an empty list.
be empty lists. For all q ∈ {1,..., n
p
} set N
q
= ∅. Set J to an empty list. -
2.
For all i ∈ {1,..., n y } calculate
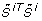 , its eigenvectors
, its eigenvectors 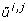 , and the corresponding eigenvalues
, and the corresponding eigenvalues 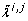 , j ∈ {1,..., n
p
}.
, j ∈ {1,..., n
p
}. -
3.
For i ∈ {1,..., n y } calculate
, , and by applying ranking criterion one to three as described in the Method section. Let 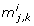 denote the k th entry of
denote the k th entry of 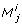 .
. -
4.
For q from 1 to n p
-
For j ∈ {1, 2, 3} and i ∈ {1,..., n y } set
.
do:
-
Only if N q ≠ ∅ append N q to the list J.
-
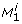 ,
, 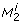 , and
, and 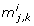 denote the k th entry of
denote the k th entry of The final ranking that combines the PCA results of all and all three criteria is given by J, where the first position in J corresponds to the least and the last position in J corresponds to the most identifiable parameter.
D: Orthogonal method
In this part we present a geometric interpretation the orthogonal method, followed by a description of algorithmic details.
Visualization of the concept of the orthogonal method
The orthogonal method is visualized in Figure 6 for q = 3. Two columns of S have already been selected and represent the first and the second column of X2 denoted by  and
and  , respectively. These two columns span the vector space V2. Without restriction this vector space is assumed to be the xy plane and k is the next parameter to be chosen.
, respectively. These two columns span the vector space V2. Without restriction this vector space is assumed to be the xy plane and k is the next parameter to be chosen.

Visualization of the concepts of the orthogonal method.
Algorithm for the orthogonal method
Algorithmic details for the orthogonal method are given below.
-
1.
Choose Δt and an initial guess p*. Initialize
 to a list of zeros.
to a list of zeros. -
2.
Calculate the sensitivity matrix S.
-
3.
Find r 1 such that
 , set
, set 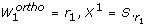 , and L 1 = {1,..., n
p
} - {r 1}.
, and L 1 = {1,..., n
p
} - {r 1}. -
4.
For q from 1 to n p
-
Calculate P q as given by equation (22).
-
Find r q such that
 , with
, with  corresponding to the k th column of P
q
.
corresponding to the k th column of P
q
. -
Set
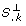 ≥ ϵ
o
:
≥ ϵ
o
:
do: set
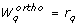 ,
,set
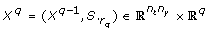 ,
,and set L q+1= L q - {r q }.
-
 to a list of zeros.
to a list of zeros. , set
, set 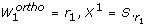 , and L 1 = {1,..., n
p
} - {r 1}.
, and L 1 = {1,..., n
p
} - {r 1}. , with
, with  corresponding to the k th column of P
q
.
corresponding to the k th column of P
q
.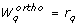 ,
,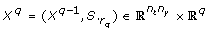 ,
,The ranking is given by Wortho. The shown implementation ignores the stopping criterion applied in the original literature, to ensure a complete ranking.
E: Computational complexity of the orthogonal and the eigenvalue method
The numerical operations of the two methods that dominate the number of necessary numerical operations are 1) matrix inversions and eigenvalue/eigenvector calculations, which both require O(N3) operations for N × N matrices, and 2) matrix multiplications, which require N·M·L operations for the multiplication of an N × M by an M × L matrix.
In what follows, we assume the eigenvalue method is used to rank all model parameters. This overestimates the computational cost of the eigenvalue method, since the method stops once an identifiable set of parameters has been found.
Computational complexity of the orthogonal method
In compact notation the orthogonal projection in iteration i, where i ∈ {1,..., n p } is arbitrary but fixed, can be written as:

The major runtime costs result from the computation 1) of Y and 2) of Y S' in equation (22). The number of operations necessary to calculate Y is:


where all iterations i = 1,..., n p have been accounted for. The first and second term in the sum of equation (23) account for the multiplication of Xiby (XiTXi)-1 (n y n t × i matrix times i × i matrix) and the inversion of the matrix XiTXi(i × i matrix), respectively. The third term accounts for the cost of multiplying XiTby Xi(i × n y n t matrix times n y n t × i). This term reduces from i2n y n t to in y n t , the cost or calculating the last row of XiTXi, since Xi-1TXi-1is available from the previous iteration:

Here  denotes the i th column of Xi. The last row is equal to the last column, since XiTXiis symmetric. The cost for i vector multiplications
denotes the i th column of Xi. The last row is equal to the last column, since XiTXiis symmetric. The cost for i vector multiplications  with 1 ≤ k ≤ i amounts to in
y
n
t
, which gives rise to the last term in the sum in equation (23).
with 1 ≤ k ≤ i amounts to in
y
n
t
, which gives rise to the last term in the sum in equation (23).
The number of operations necessary to calculate Y S' is:

The first term in the sum accounts for the multiplication of Y by S' (n y n t × i matrix times i × n p matrix). The second term accounts for the calculation of S' from the product XiTS (i × n y n t matrix times n y n t × n p matrix). The latter reduces to the cost n y n t n p for calculating the last row of S', since Xi-1TS is vailable from the previous iteration:

where denotes the last column of Xiand S.
i
denotes the i th column of S.
The subtraction of S from Y S' (n y n t × n p matrix minus n y n t × n p matrix) in equation (22) requires O(n y n t n p ) operations and therefore can be neglected.
In summary the dominant parts in equation (24) and (25) result in a computational complexity of order  .
.
Computational complexity of the eigenvalue method
For ease of presentation the description of the algorithm in the Methods section slightly differs from the actual implementation. In the implemented version the Hessian matrix H = STS has to be calculated only once at the beginning of the algorithm, which requires  operations (multiplication of a n
p
× n
y
n
t
matrix with a n
y
n
t
× n
p
matrix). In each iteration i, the current Hessian Hican be obtained by removing the rows and columns from H that correspond to fixed parameters. In each iteration the eigenvalues of the current Hessian matrix have to be calculated. The number of operations necessary for the eigenvalue method is as follows.
operations (multiplication of a n
p
× n
y
n
t
matrix with a n
y
n
t
× n
p
matrix). In each iteration i, the current Hessian Hican be obtained by removing the rows and columns from H that correspond to fixed parameters. In each iteration the eigenvalues of the current Hessian matrix have to be calculated. The number of operations necessary for the eigenvalue method is as follows.


The first term accounts for the initial calculation of the Hessian matrix. The second term accounts for the eigenvalue calculation.
Comparing computational complexity of the eigenvalue and the orthogonal method
The computational complexity of the eigenvalue method is of order  (see equation (27)), whereas the computational complexity of the orthogonal method is of order (see equation (24)). For a comparison we have to distinguish between the following three cases. In the first case we assume n
y
n
t
≤ n
p
. In this case the complexity of both methods is dominated by the term
(see equation (27)), whereas the computational complexity of the orthogonal method is of order (see equation (24)). For a comparison we have to distinguish between the following three cases. In the first case we assume n
y
n
t
≤ n
p
. In this case the complexity of both methods is dominated by the term  and both method are equally efficient. In the examples treated here, this case does not occur. In the second case we assume
and both method are equally efficient. In the examples treated here, this case does not occur. In the second case we assume  . Here the computational complexity of the eigenvalue and the orthogonal method reduce to
. Here the computational complexity of the eigenvalue and the orthogonal method reduce to  and
and  , respectively. This case applies to the MAP-kinase example and the eigenvalue method is faster than the orthogonal method. The difference is the more pronounced the larger n
y
n
t
- n
p
. In the last case we assume that . This is true in the JAK-STAT and the NF-κ B example. Here the complexity of the eigenvalue method and the orthogonal method reduce to and
, respectively. This case applies to the MAP-kinase example and the eigenvalue method is faster than the orthogonal method. The difference is the more pronounced the larger n
y
n
t
- n
p
. In the last case we assume that . This is true in the JAK-STAT and the NF-κ B example. Here the complexity of the eigenvalue method and the orthogonal method reduce to and  , respectively. In this case the eigenvalue method is an order of magnitude in the number of parameters faster than the orthogonal method.
, respectively. In this case the eigenvalue method is an order of magnitude in the number of parameters faster than the orthogonal method.
F: Correlation is not equal to linear dependence
In order to show that a correlation of ± 1 between two vectors does not necessarily imply their linear dependence, we present a simple counter-example. Consider the vectors x = (1, -1)Tand y = (2, 0)T. According to equation (13) the correlation corr(x, y) = 1 results. Clearly, however, x and y are linearly independent. A set of parameters that are found to be unidentifiable with the correlation method may therefore contain false positives.
References
Lipniacki T, Paszek P, Brasier ARAR, Luxon B, Kimmel M: Mathematical model of NF-kappaB regulatory module. J Theor Biol. 2004, 228 (2): 195-215. 10.1016/j.jtbi.2004.01.001
Yamada S, Shiono S, Joo A, Yoshimura A: Control mechanism of JAK/STAT signal transduction pathway. FEBS Lett. 2003, 534 (1–3): 190-196. 10.1016/S0014-5793(02)03842-5
Schoeberl B, Eichler-Jonsson C, Gilles ED, Mueller G: Computational modeling of the dynamics of the MAP kinase cascade activated by surface and internalized EGF receptors. Nat Biotechnol. 2002, 20 (4): 370-375. 10.1038/nbt0402-370
Walter E, Pronzato L: Identification of parametric models from experimental data. 1997, Springer Berlin
Swameye I, Muller TG, Timmer J, Sandra O, Klingmuller U: Identification of nucleocytoplasmic cycling as a remote sensor in cellular signaling by databased modeling. Proc Natl Acad Sci USA. 2003, 100 (3): 1028-1033. 10.1073/pnas.0237333100
Xia X, Moog CH: Identifiability of nonlinear systems with application to HIV/AIDS models. IEEE T Automat Contr. 2003, 48 (2): 330-336. 10.1109/TAC.2002.808494.
Jeffrey A, Xia X: Identifiability of HIV/AIDS models. Deterministic and Stochastic Models of AIDS Epidemics and HIV Infections with Intervention. 2005, 255-286. full_text.
Wu H, Zhu H, Miao H, Perelson A: Parameter Identifiability and Estimation of HIV/AIDS Dynamic Models. Bulletin of Mathematical Biology. 2008, 70 (3): 785-799. 10.1007/s11538-007-9279-9
Zak DE, Gonye GE, Schwaber JS, Doyle FJ: Importance of input perturbations and stochastic gene expression in the reverse engineering of genetic regulatory networks: insights from an identifiability analysis of an in silico network. Genome Res. 2003, 13 (11): 2396-2405. 10.1101/gr.1198103
Rodriguez-Fernandez M, Mendes P, Banga JR: A hybrid approach for efficient and robust parameter estimation in biochemical pathways. Biosystems. 2006, 83 (2–3): 248-265. 10.1016/j.biosystems.2005.06.016
Jacquez JA, Perry T: Parameter estimation: local identifiability of parameters. American Journal of Physiology-Endocrinology And Metabolism. 1990, 258 (4): 727-736.
Ljung L, Glad T: On global identifiability for arbitrary model parametrizations. Automatica. 1994, 30 (2): 265-276. 10.1016/0005-1098(94)90029-9.
Pohjanpalo H: System identifiability based on power-series expansion of solution. Math Biosci. 1978, 41 (1–2): 21-33. 10.1016/0025-5564(78)90063-9.
Godfrey K, DiStefano J: Identifiability of Parametric Models. 1987, Pergamon, Oxford
Audoly S, Bellu G, D'Angiò L, Saccomani MP, Cobelli C: Global identifiability of nonlinear models of biological systems. IEEE Trans Biomed Eng. 2001, 48: 55-65. 10.1109/10.900248
Walter E, Braems I, Jaulin L, Kieffer M: Guaranteed Numerical Computation as an Alternative to Computer Algebra for Testing Models for Identifiability. Lecture Notes in Computer Science. 2004, 124-131.
Vajda S, Rabitz H: State isomorphism approach to global identifiability of nonlinear-systems. IEEE T Automat Contr. 1989, 34 (2): 220-223. 10.1109/9.21105.
Chappell M, Godfrey K: Structural identifiability of the parameters of a nonlinear batch reactor model. Math Biosci. 1992, 108 (2): 241-51. 10.1016/0025-5564(92)90058-5
Peeters RLM, Hanzon B: Identifiability of homogeneous systems using the state isomorphism approach. Automatica. 2005, 41 (3): 513-529. 10.1016/j.automatica.2004.11.019.
Asprey SP, Macchietto S: Statistical tools for optimal dynamic model building. Comput Chem Eng. 2000, 24 (2–7): 1261-1267. 10.1016/S0098-1354(00)00328-8.
Asprey SP, Macchietto S: Designing robust optimal dynamic experiments. J Process Control. 2002, 12 (4): 545-556. 10.1016/S0959-1524(01)00020-8.
Asprey SP, Macchietto S: Dynamic model development: Methods, Theory and Applications. 2003, Elsevier, Amsterdam, The Netherlands
Brun R, Reichert P, Kunsch HR: Practical identifiability analysis of large environmental simulation models. Water Resour Res. 2001, 37 (4): 1015-1030. 10.1029/2000WR900350.
Yao KZ, Shaw BM, Kou B, McAuley KB, Bacon DW: Modeling ethylene/butene copolymerization with multi-site catalysts: Parameter estimability and experimental design. Polym React Eng. 2003, 11 (3): 563-588. 10.1081/PRE-120024426.
Jacquez JA, Greif P: Numerical parameter identifiability and estimability: Integrating identifiability, estimability, and optimal sampling design. Math Biosci. 1985, 77 (1–2): 201-227. 10.1016/0025-5564(85)90098-7.
Vajda S, Rabitz H, Walter E, Lecourtier Y: Qualitative and quantitative identifiability analysis of nonlinear chemical kinetiv-models. Chem Eng Commun. 1989, 83: 191-219. 10.1080/00986448908940662.
Degenring D, Froemel C, Dikta G, Takors R: Sensitivity analysis for the reduction of complex metabolism models. J Process Control. 2004, 14 (7): 729-745. 10.1016/j.jprocont.2003.12.008.
Froemel C: Parameterreduktion in Stoffwechselmodellen mit Methoden der Statistik. Master's thesis. 2003, Fachhochschule Aachen, Abteilung Juelich, Fachbereich Physikalische Technik, Studienrichtung Technomathematik
Hengl S, Kreutz C, Timmer J, Maiwald T: Data-based identifiability analysis of non-linear dynamical models. Bioinformatics. 2007, 23 (19): 2612-2618. 10.1093/bioinformatics/btm382
Chu Y, Hahn J: Parameter Set Selection via Clustering of Parameters into Pairwise Indistinguishable Groups of Parameters. Industrial & Engineering Chemistry Research. 2009
Quaiser T, Marquardt W, Moennigmann M: Local Identifiability Analysis of Large Signaling Pathway Models. 2nd Conference Foundation of Systems Biology in Engineering, Proceedings Plenary and Contributed Papers, ISBN 978-3-8167-7436-5. Edited by: Allgoewer F, Reuss M. 2007, 465-470. Stuttgart: Fraunhofer IRB Verlag
Schittkowski K: Experimental design tools for ordinary and algebraic differential equations. Ind Eng Chem Res. 2007, 46 (26): 9137-9147. 10.1021/ie0703742.
Li S, Petzold L: Design of new Daspk for Sensitivity Analysis. Technischer Report. 1999
Beck J, Arnold K: Parameter estimation in engineering and science. 1977, Wiley New York
Zill D, Cullen M: Advanced Engineering Mathematics. 2006, Jones & Bartlett Publishers
Gadkar KG, Gunawan R, Doyle FJ: Iterative approach to model identification of biological networks. BMC Bioinformatics. 2005, 6: 155- 10.1186/1471-2105-6-155
Yue H, Brown M, Knowles J, Wang H, Broomhead DS, Kell DB: Insights into the behaviour of systems biology models from dynamic sensitivity and identifiability analysis: a case study of an NF-kappaB signalling pathway. Mol BioSyst. 2006, 2 (12): 640-649. 10.1039/b609442b
Grewal MS, Glover K: Identifiability of linear and nonlinear dynamical-systems. IEEE T Automat Contr. 1976, 21 (6): 833-836. 10.1109/TAC.1976.1101375.
Heinrich PC, Behrmann I, Haan S, Hermanns HM, Mueller-Newen G, Schaper F: Principles of interleukin IL-6-type cytokine signalling and its regulation. Biochem J. 2003, 374 (Pt 1): 1-20. 10.1042/BJ20030407
Berkers JA, en Henegouwen van Bergen PM, Boonstra J: Three classes of epidermal growth factor receptors on HeLa cells. J Biol Chem. 1991, 266 (2): 922-927.
Chung JC, Sciaky N, Gross DJ: Heterogeneity of epidermal growth factor binding kinetics on individual cells. Biophys J. 1997, 73 (2): 1089-1102. 10.1016/S0006-3495(97)78141-4
Krishna S, Jensen MH, Sneppen K: Minimal model of spiky oscillations in NF-kappaB signaling. Proc Natl Acad Sci USA. 2006, 103 (29): 10840-10845. 10.1073/pnas.0604085103
Strang G: Introduction to Linear Algebra. 2003, Wellesley Cambridge Pr
Acknowledgements
We gratefully acknowledge funding by Deutsche Forschungsgemeinschaft (DFG) under grant MO 1086/5-1. We thank Prof. F. Schaper for providing his insight on biological aspects and C. Michalik for fruitful discussions. A previous version of this paper was presented at the 2nd Foundations of Systems Biology in Engineering conference, Stuttgart, Germany, Sept. 2007.
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
TQ and MM developed the eigenvalue method. The discussed method were implemented and compared by TQ. TQ and MM wrote the article.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Quaiser, T., Mönnigmann, M. Systematic identifiability testing for unambiguous mechanistic modeling – application to JAK-STAT, MAP kinase, and NF-κ B signaling pathway models. BMC Syst Biol 3, 50 (2009). https://doi.org/10.1186/1752-0509-3-50
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1752-0509-3-50